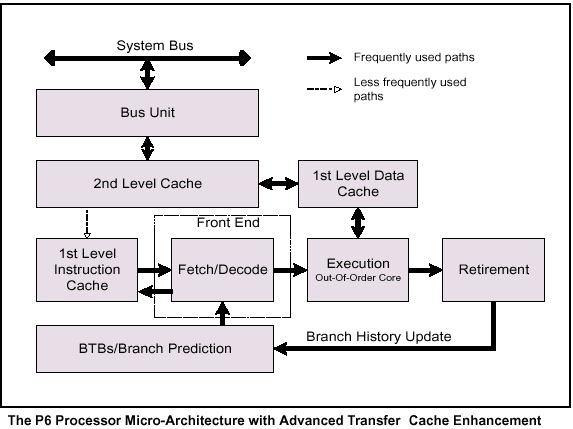
The Intel(R) Pentium(R) Pro processor introduced a new microarchitecture for the Intel IA-32 processors, commonly referred to as P6 family microarchitecture. The P6 family microarchitecture was later enhanced with an on-die, 2nd level cache, called Advanced Transfer Cache. This microarchitecture is a three-way superscalar, pipelined architecture. The term ”r;three-way superscalar” means that using parallel processing techniques, the processor is able on average to decode, dispatch, and complete execution of (retire) three instructions per clock cycle. To handle this level of instruction throughput, the P6 family use a decoupled, 12-stage superpipeline that supports out-of-order instruction execution.
Conceptual view of the P6 family microarchitecture pipeline
The microarchitecture pipeline is divided into four sections (the 1st level and 2nd level caches, the front end, the out-of-order execution core, and the retire section). Instructions and data are supplied to these units through the bus interface unit.
To insure a steady supply of instructions and data to the instruction execution pipeline, the P6 family microarchitecture incorporates two cache levels. The first-level cache provides an 8-KByte instruction cache and an 8-KByte data cache, both closely coupled to the pipeline. The second-level cache is a 256-KByte, 512-KByte, or 1-MByte static RAM that is coupled to the core processor through a full clock-speed 64-bit cache bus.
The centerpiece of the P6 family microarchitecture is an innovative out-of-order execution mechanism called ”r;dynamic execution.” Dynamic execution incorporates three data-processing concepts:
Deep branch prediction.
Dynamic data flow analysis.
Speculative execution.
Branch prediction is a modern technique to deliver high performance in pipelined microarchitectures. It allows the processor to decode instructions beyond branches to keep the instruction pipeline full. The P6 family implements highly optimized branch prediction algorithm to predict the direction of the instruction stream through multiple levels of branches, procedure calls, and returns.
Dynamic data flow analysis involves real-time analysis of the flow of data through the processor to determine data and register dependencies and to detect opportunities for out-of-order instruction execution. The out-of-order execution core can simultaneously monitor many instructions and execute these instructions in the order that optimizes the use of the processor's multiple execution units, while maintaining the data integrity. This out-of-order execution keeps the execution units busy even when cache misses and data dependencies among instructions occur.
Speculative execution refers to the processor's ability to execute instructions that lie beyond a conditional branch that has not yet been resolved, and ultimately to commit the results in the order of the original instruction stream. To make speculative execution possible, the P6 family microarchitecture decouples the dispatch and execution of instructions from the commitment of results. The processor's out-of-order execution core uses data-flow analysis to execute all available instructions in the instruction pool and store the results in temporary registers.
The retirement unit then linearly searches the instruction pool for completed instructions that no longer have data dependencies with other instructions or unresolved branch predictions.
When completed instructions are found, the retirement unit commits the results of these instructions to memory and/or the IA-32 registers (the processor's eight general-purpose registers and eight x87 FPU data registers) in the order they were originally issued and retires the instructions from the instruction pool.
Combining branch prediction, dynamic data-flow analysis and speculative execution, the dynamic execution capability of the P6 family microarchitecture removes the constraint of linear instruction sequencing between the traditional fetch and execute phases of instruction execution. Thus, the processor can continue to decode instructions even when there are multiple levels of branches. Branch prediction and advanced decoder implementation work together to keep the instruction pipeline full. Subsequently, the out-of-order, speculative execution engine can take advantage of the processor's six execution units to execute instructions in parallel. And finally, it commits the results of executed instructions in original program order to maintain data integrity and program coherency.